

スーパーコンピュータ「不老」の概要と「富岳」型Type I サブシステム
はじめに
名古屋大学情報基盤センターは、2020年7月1日より、スーパーコンピュータ「不老」(以降、「不老」と明記します。)を設置し、サービスを開始しました。ここでは、情報学の観点から「不老」のシステムの説明をしていこうと思います。
スーパーコンピュータとは
まず、スーパーコンピュータ(以降、スパコンと記載)とは何かを説明します。多くの人が思っているかもしれませんが、必ずしも人工知能搭載のコンピュータではないです(ただし、現在のスパコンでは、人工知能分野の機械学習が得意なスパコンがあります。)
いろいろな定義があるため、スパコンはこれだ、という定義が無いのが現状です。しかし、大まかにいうと、現在の最高レベルの演算性能をもつ計算機のことです。経験的には、PCの1000倍以上高速で、1000倍以上大容量なメモリをもつ計算機が、スーパーコンピュータであることが多いです。ここで、速度が1000倍高速だと、世界が全く異なることに注意してください。たとえば、人の歩行速度は、時速として5kmぐらいのものだと思いますが、この1000倍の速度は時速 5000kmにもなってしまいます。これは、ジェット機の速度の5倍と考えられる。これだけでも、想像を絶する速度だということがわかると思います。 最新鋭スパコンの能力は、皆さんの周りにあるパソコンの10万倍以上高速ですので、さらに想像を絶する速度であるといえるでしょう。
一方、スパコンの世界で用いる単位があります。それを紹介します。まず、TFLOPS(テラ・フロップス、Tera Floating Point Operations Per Second)という単位があります。これは、 1秒間に1回の演算能力(浮動小数点演算、つまり、実数を計算機で表現される数値に対して、足し算、掛け算、割り算、乗算をそれぞれ1回の計算とする)が、1FLOPSです。あとは単位で、K(キロ)は 1,000(千)、M(メガ)は 1,000,000(百万)、G(ギガ)は 1,000,000,000(十億)、T(テラ)は 1,000,000,000,000 (一兆)ですから、1TFLOPSは、1秒間に一兆回の計算能力があることをいいます。
スパコンの全体性能としてよく使う単位は、Tの1000倍の、P (ペタ) で 1,000,000,000,000,000 (千兆=0.1京)の計算能力です。
スパコンでの高速化の仕組み
次に、スパコンでの高速化はどのように行っているか、簡単に説明します。結論から言うと、全て、「並列化」によってされています。計算のいろいろなレベルで並列化をして、高速化を達成しているのですが、最初に思いつく方法は、計算機をたくさん並べて、同時に計算することでしょう。実際、スパコンでは、この考え方で計算能力を高めています。
では、最新のスパコンは、どれだけの数の計算機を並べて構成されているのでしょうか?
2021年現在、計算能力の最も高いスパコンでは、約700万台以上の計算機を連結し、システムを構成しています。
「不老」のシステム概要
2020年7月1日に稼働を開始した、「不老」のシステム概要を紹介します。
まず全体性能ですが、15.88PFLOPSあります。「不老」は単一のシステムではなく、複数のサブシステムにより構成されています。
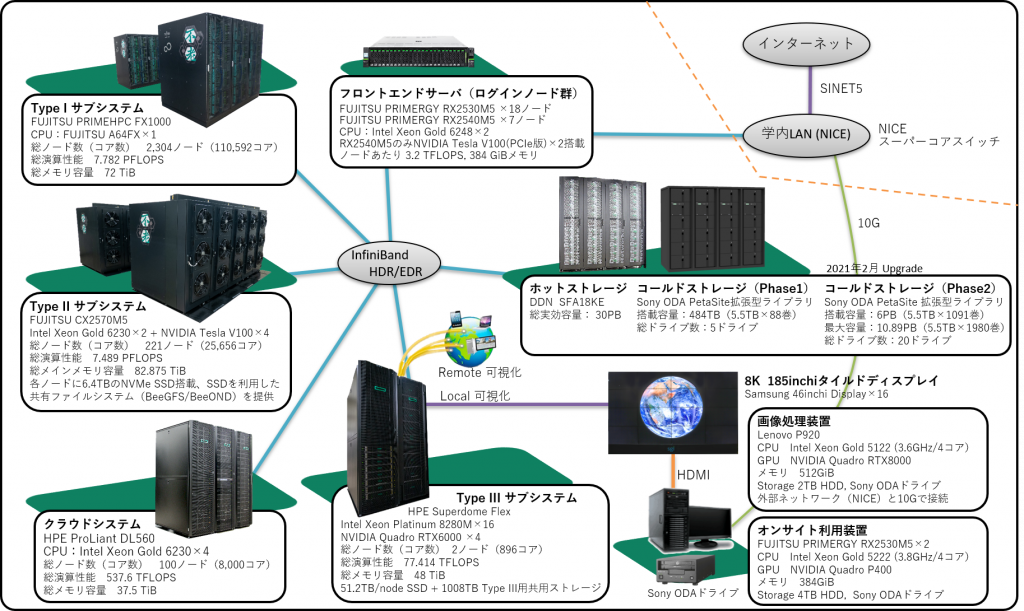
まず、TypeⅠサブシステムです。後ほど紹介しますが、2021年3月現在、世界一高速なスパコンである、スーパーコンピュータ「富岳」と同型のもので、7.782PFLOPSです。次に、Type IIサブシステムですが、これは、機械学習に向いたGPU (Graphics Processing Unit)を搭載したシステムで、7.489PFLOPSの計算性能を有します。また、Type IIIサブシステムは、全体で48TBという大規模なメモリを有しているもので、計算能力は77.414TFLOPSです。最後に、クラウドシステムとして、537.6TFLOPSの計算能力があります。以上の4サブシステムから、「不老」は構成されています。
また、スパコンにおいては、大規模データの蓄積も重要です。現在、データサイエンス、ビッグデータ、Society5.0というIT分野のキーワードをよく聞くと思いますが、いずれも、大規模なデータの蓄積が必要となります。
「不老」では、2種類のファイルシステムにより、大規模データの蓄積が可能です。まずは、ホットストレージです。ホットストレージとは、常時ファイルシステムを立ち上げておく形式の蓄積装置です。皆さんがお使いの、PCのハードディスクと思ってよいでしょう。ただし、データの堅牢性(データが消えない、消えても再生できる)の点が、スパコンでは極めて高く設計されており、PCでは全く異なるので注意してください。容量の面では、「不老」ホットストレージは、30.44 PBになります。容量だけで比べると、たとえば、1TBのハードディスク3万個分に相当します。
次に、コールドストレージによるデータ蓄積ができます。コールドストレージとは、常時、ファイルシステムを立ち上げておく必要が無く、必要時に立ち上げてデータを出し入れするものです。さらに「不老」では、コールドストレージの媒体に光ディスクを採用しています。この光ディスクは特殊であり、理論上、100年たってもデータが消えず、水にぬれてもデータが消えないという特徴があるものを採用しています。そのため、大変、強固に、かつ、長期間、大事なデータを蓄積できます。コールドストレージ容量として6PBあり、スパコンシステムとしては国内外で最大規模の容量のものです。
また、「不老」は可視化システムに連結しており、計算結果の可視化機能も豊富です。ここでは、以下に簡単な概要を載せるだけにします。

次に、計算性能について説明します。計算性能の評価をするとき、標準的なプログラムを動かして性能を測定することをします。このようなことを、ベンチマーキングといいます。 スパコンでのベンチマーキングには、多種のプログラムが使われるのですが、その中でも有名なもののいくつかについて説明し、「不老」の性能評価結果を紹介します。
まずは、TOP500による、HPLというベンチマークです[1]。HPLは、連立一次方程式の求解をして、その演算性能を求めるものです。連立一次方程式とは、中学校で習うとおもいますが、たとえば 3x + y = 4、x +5y=9 で、解のxとyを求める演算と考えてよいです。この変数(x, y)が、数百万個以上ある、超大規模な連立一次方程式をスパコンで解かせているものです。「不老」TypeⅠによるHPLの結果は、6.617 PFLOPSで、これは2020年11月では、世界 36位、国内5位の性能です。
一方、HPLより、現実的な計算で使われるベンチマークとして、HPCG[2]があります。HPCGは、産業利用で多い疎行列反復解法のベンチマークです。疎行列反復解法とは、HPLと同じように連立一次方程式を解くのですが、0の多い行列を、繰り返し計算で解きます。ここで0の多い行列とは、連立一次方程式において、ところどころ変数が無い方程式を解くというものです。例えば、3x + 0y + z = 4、0x + 5y +9z = 2、のような連立一次方程式です。「不老」TypeⅠサブシステムのHPCGの性能は、2020年11月で、0.231 PFLOPS、 世界 16位、国内4位です。
最後に、現在流行している、人工知能で必要な演算を行うベンチマークであるHPL-AI [3]を紹介します。人工知能で行われる機械学習は、演算の多くは、通常の演算精度より低い演算精度で行うことができます。そのため、通常の演算精度と、より低い演算精度の計算を組み合わせ、連立一次方程式を解き性能を評価するのが、HPL-AIです。「不老」TypeⅠサブシステムのHPL-AIの性能は、30.1 PFLOPSであり、2020年11月現在、世界 5位、国内2位(1位は、世界および国内共に「富岳」)という、極めて高い性能を有します。
以上から、「不老」は国内トップクラスのスパコンであるといえますが、どのような計算がなされているのでしょうか?答えは、いろんな計算がなされています。ここでは、名古屋大学で特徴的な計算を列挙するのみに留めます。
- スーパー台風解析
- プラズマシミュレーション
- 医用画像診断支援/医用画像処理
- COVID-19分子解析
- AIによる気象予測
「不老」TypeⅠサブシステム ―スーパーコンピュータ「富岳」型―
ここで、「不老」TypeⅠサブシステムについて、説明します。

先ほど述べたように、TypeⅠサブシステムは、2021年3月現在、世界一のスパコンである、スーパーコンピュータ「富岳」と同型のシステムになります。同型とは、規模(演算性能)は、「富岳」に対してTypeⅠサブシステムは、70分の1ほどとなりますが、ハードウェアとしては同一ということです。そのため、Type Iサブシステムで開発したプログラムは、そのまま「富岳」でも動きます。そのため、「不老」のユーザは、簡便に「富岳」へ移行できるため、国策スパコンの利用推進にも、名古屋大学情報基盤センターは貢献しています。
以下に、Type Iサブシステムの構成を示します。

Type IサブシステムのCPUには、ARMを採用しています。ARMは、携帯電話や車載システムなど多くのシステムで採用されているCPUであり、みなさんは知らないかもしれませんが、ありふれているCPUの1つです。そのCPUを、「富岳」では採用しました。ただし、通常の車載システムなどで使われているARMのCPUに対して、数値計算に特化した拡張がなされています。その拡張の1つが、同時に計算ができる並列化の能力を高める仕組を実装したものです。それにより、1つのCPUで、倍精度で3.3792 TFLOPS、単精度で 6.7584 TFLOPSの性能があります。また、機械学習で用いる半精度では、13.5168 TFLOPSの性能があります。この一方、アシスタントコア、という特別なCPUが2個、1ノード(メモリが直接連結している単位)毎にあります。アシスタントコアは、オペレーティングシステム特有の処理や、通信処理専用のCPUです。アシスタントコアにより、並列実行時の性能が高くなり、「富岳」型以外のスパコンより高い効率で処理を走らせることが期待できます。
一方、スパコンでは、メモリへのデータのアクセス速度も高速なものを採用しています。ここでは、HBM2という技術により、1秒間に1024GBというデータ量をアクセスできます。これは1TBで、つまり、1秒で、1TBのハードディスクの中身を読み書きできる性能といえます。いかに高速かがわかると思います。
TypeⅠサブシステム全体では、2,304ノードで構成されており、これは、内部の計算要素にすると、110,592コアになります。つまり、11万台にも及ぶ計算機が同時に動いている、といえます。
また、多数の計算機を連結するため、通信網も高性能なものを採用しています。TofuインターコネクトD というものです。TofuインターコネクトDの性能は、各ノードは周囲の隣接ノードへ同時に合計 40.8 GB/s で通信ができ、かつ、これは、双方向です。1リンク当たり 6.8 GB/s ×双方向であり、6リンク同時通信可能です。つまり、各ノードから、40.8Gbのデータを、1秒間に送受信する能力がある通信網です。
おわりに
限られた紙面での紹介でありましたが、スーパーコンピュータ「不老」に代表される最先端のスパコンでは、あらゆるところに、現在の最高レベルの高性能化の仕組みが搭載されていることが、お分かりいただけたかと思います。ここでは主に、ハードウェア上の内容を説明しました。しかし高速化の方法は、ハードウェアのみには留まりません。
本稿では説明できませんでしたが、コンパイラやプログラミングを含むプログラム上の工夫、および、動かすソフトウェア上の工夫(数値解析、アルゴリズムなど)が多数行われています。スパコンを利用する分野では、これらの知見をすべて活用し、世界最高レベルの研究がなされています。
このように、高い性能の計算を研究する情報学の分野を、高性能計算学といいます。片桐・大島研究室では、スパコンを用いた高性能計算を研究しています。ご興味ある読者がいましたら、以下のHPを参照いただければと思います。
参考:片桐・大島研究室HP
http://www.hpc.itc.nagoya-u.ac.jp/
参考文献
[1] TOP500
[2] HPCG Benchmark
https://www.hpcg-benchmark.org/
[3] HPL-AI Mixed-Precision Benchmark
https://icl.bitbucket.io/hpl-ai/
著者紹介
片桐孝洋
名古屋大学 大学院情報学研究科 情報システム学専攻 教授
専門は、高性能計算、自動チューニング、並列処理、並列プログラミング教育、など。 著書には、「スパコンプログラミング入門-並列処理とMPIの学習-」(東京大学出版会、2013年)、「スパコンを知る:その基礎から最新の動向まで」、岩下武史、片桐孝洋、高橋大介著(東京大学出版会、2015年)、「並列プログラミング入門:サンプルプログラムで学ぶOpenMPとOpenACC」(東京大学出版会、2015年)、および、「数値線形代数の数理とHPC」、(日本応用数理学会(監修)、櫻井鉄也、松尾宇泰、片桐孝洋(編)、共立出版、2018年)、など多数。