

スーパーコンピュータ「不老」とGPUスパコン
スーパーコンピュータ「不老」(以下、「不老」)は主に4つの主要な計算サブシステムと2種類のストレージによって構成されています。本記事ではその中でも特にType IIサブシステムについて紹介したいと思います。
スーパーコンピュータとGPU
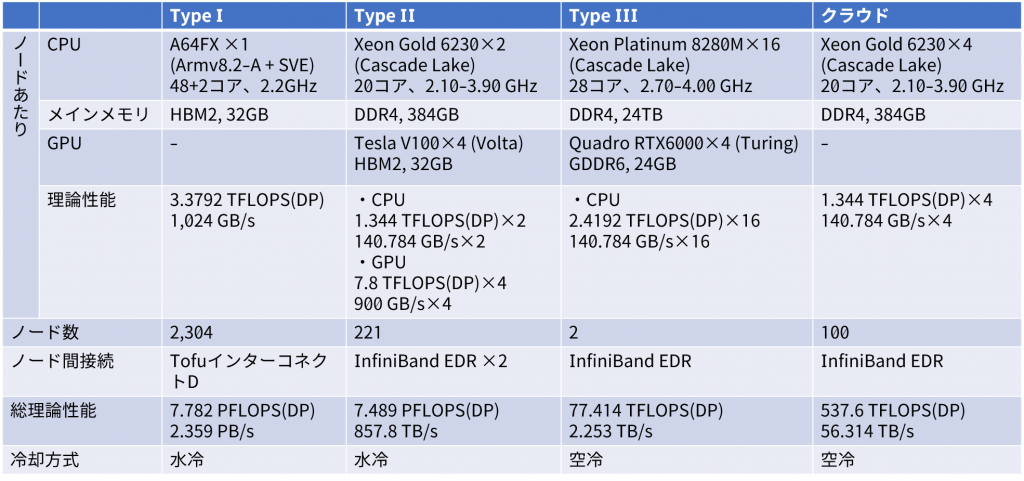
Type IIサブシステムは221のノードにより構成されたサブシステムであり、その総理論演算性能は7.489PFOPSです。Type IIサブシステムは表1のような構成のハードウェアです。1ノードはサーバ1台だと思ってください。PFLOPSは性能の単位(指標)であり、実数の加算や乗算を1秒間に1,000,000,000回行えることを意味します。表2に示すとおり、サブシステムあたりの性能(総理論性能PFLOPS)はType IIサブシステムよりType Iサブシステムの方が少しだけ上ですが、ノード数が約10倍違います。つまり、1ノードあたりの性能はType IサブシステムよりもType IIサブシステムの方がずっと高いことを意味します。この非常に高いノードあたり性能を支えているのがGPUという演算装置であり、GPUこそがType IIサブシステムの最大の特徴なのです。
表1 「不老」Type IIサブシステムの詳細構成

表2 「不老」を構成する各計算サブシステムの性能
それではGPUとはいったいなんなのでしょうか。GPUはGraphics Processing Unitを省略した名称であり、日本語で言うなら画像処理装置、三次元CGの描画や画面出力に欠かせないハードウェアです。GPUはパソコンやゲーム機、スマートフォンなどがディスプレイに映像を出力するのに欠かせないハードウェアであるため皆さんもお世話になっているはずです。しかし、薄型のノートPCや安価なパソコン、スマートフォンにおいては単体のGPU製品の代わりにGPUの機能を統合したCPUが搭載されているため、気にしたことがない人も多いかもしれません。パソコンの自作をしたことがある人であれば、パソコンショップや家電量販店のパソコンパーツ売り場でグラフィックスカードやビデオカードとして販売されているものと言えばわかるでしょうか。最新のパソコン用ゲームやeスポーツを楽しんでいる人にはなじみがあるかもしれませんね。
実は高性能なGPUは計算ハードウェアとしても高い性能を備えているため、ここ10年ほど科学技術計算用のサーバやスーパーコンピュータにGPUを搭載するのが一つのトレンドとなっています。GPUが高い性能を備えている、といってもピンとこないかもしれませんが、例えば最新のパソコンやゲーム機の映像の中には現実かと思うくらいリアリティのある光や影を描いているものがありますし、表示されるディスプレイは4Kなどの高解像度なものが増えています。高解像度で高精細な映像を高速に作るためには大量の計算を高速に行わねばならないため、GPUには高い演算性能が必要なのです。ただし、画像処理や映像処理に必要な計算の中には計算順序が重要でないもの、同時に行えるものがたくさんあります。そのため、GPUもたくさんの計算を同時に行えるようにすることで性能を高めてきました。その一方で、画像処理に必要な計算の種類はある程度限られており、どんな計算でも高速に行える必要はありません。そのため、GPUはCPUと比べて限られた種類の計算をたくさん高速に行えることが求められてきたのです。
興味深いことに、画像処理に必要な計算と科学技術計算に必要な計算には共通点がありました。例えば三次元画像処理においては位置や色を計算する際に4×4の行列に対する加算や乗算が多用されますが、行列計算は科学技術計算においても特に重要な計算です。そこで、画像処理用に作られたハードウェアであるGPUを科学技術計算に使おうと考える人が出てきました。最初の頃はGPUのできることに様々な制限があったため、複雑なアルゴリズムを実装するのが困難だったり、良い性能がでなかったりして大変でしたが、GPUを作るメーカー側の協力もあって科学技術計算分野におけるGPUの有効性が認められてきました。いまでは1台のPCやワークステーションから超大規模なスーパーコンピュータまで、様々なシステムでGPUが活用されています。
ここで重要なのは、CPUとGPUはできること・得意なことが同じではないということです。いくらGPUの理論演算性能が高いといっても、GPUに適した処理でないと高い性能は出せません。そのため、GPUを大量に踏査したスーパーコンピュータもあれば、GPUをまったく搭載しないスーパーコンピュータもあるのです。例えばスーパーコンピュータの性能ランキングの中でも最も有名なTOP500ランキングは、大規模な連立一次方程式を解く速度を元にランク付けを行っていますが、2020年11月の時点では500システム中140システムがNVIDIA社のGPUを搭載しています。「不老」はGPUを搭載しないType IサブシステムとGPUをたくさん搭載したType IIサブシステムの両方を提供することで、様々な計算需要に応えています。
GPUと機械学習とスーパーコンピュータ
GPUは機械学習を高速に行えるハードウェアとしても注目されています。機械学習に有用であることがGPUの普及を後押しした最大の要因の一つと言っても過言ではないでしょう。GPUが機械学習を高速に行える主な理由は、行列計算性能の高さとメモリ性能の高さにあります。しかも、機械学習に欠かせない行列計算を高速に行える点が注目されGPUの活用が進んできたところに、さらに機械学習向けの専用計算回路を搭載したGPUが登場することで、さらにGPUの活用が進みました。
「不老」には、この「GPU向けの専用計算回路」(Tensor Core)が搭載されたGPU(NVIDIA Tesla V100)が搭載されています。国内の情報基盤センター系のスーパーコンピュータにはGPUを搭載したものが増えてきていますが、この専用計算回路を搭載したタイプのGPUを大規模に搭載したスーパーコンピュータはまだ珍しいため、活用が期待されます。
機械学習は研究対象としても研究の道具としても非常に注目されており人気が高く、様々な分野で用いられている技術です。多くの利用者に「不老」を機械学習のために便利に活用してもらうには、利用するためのソフトウェアやドキュメントを充実させることも重要です。様々な利用者がそれぞれ個別の使い方をするものをサポートすることは容易ではありませんが、幸いにも多くの利用者はTensorFlowやPyTorchなどの機械学習フレームワークを使っていると思われるため、それらを使いやすいようにサポートすることで多くの利用者をカバーできます。そこで「不老」では、TensorFlowやPyTorchをすぐに利用できるように準備しているのに加えて、ソフトウェアや実行環境の共有(配布)によく使われているコンテナの利用をサポートしています。現在は機械学習環境の導入にDockerがよく用いられていますが、Dockerは共有システムで利用するには向いていないため、互換性のあるSingularityを提供しています。また、主に学習の際に多くのファイルを高速に処理したいという需要も考慮し、Type IIサブシステムの各計算ノードには高速なSSDが搭載されていますさらに、複数ノードを用いた大規模な分散機械学習が高速に行えるよう、ノード間は高速なInfiniBandネットワークで接続されています。
どのような利用者の需要にも十分に応える、というのは流石に難しいかもしれませんが、「不老」はこのように様々な最新技術を用いた計算機環境を提供し、皆様の研究利用をサポートしています。年に数回の講習会も継続して実施予定であり、「不老」の利用資格さえあればユーザ以外の方も参加できるため、興味を持った方は是非参加してみてください。